7/8/2021
•
EN
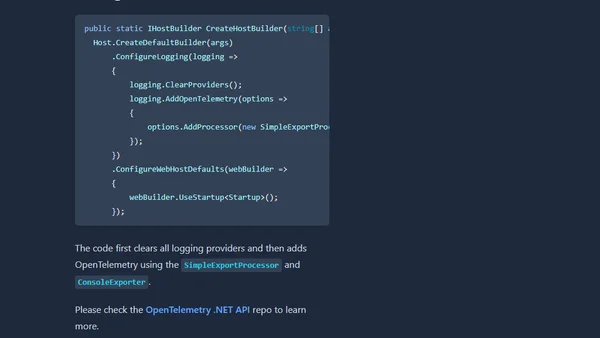
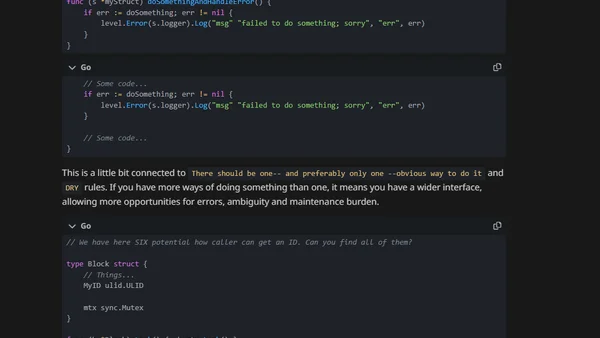
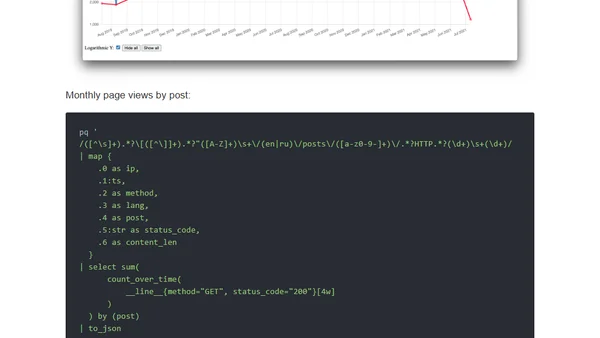
pq - parse and query log files as time series
Introducing pq, a Rust-based tool for parsing and querying log files as time series data with PromQL-like syntax.