2/12/2024
•
EN
Partitioning Practices in Apache Hive and Apache Iceberg
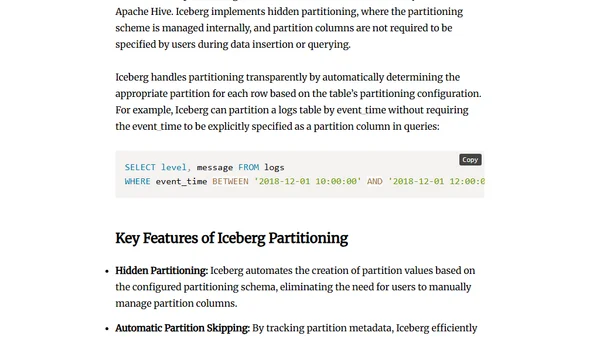
Compares partitioning techniques in Apache Hive and Apache Iceberg, highlighting Iceberg's advantages for query performance and data management.