1/30/2026
•
EN
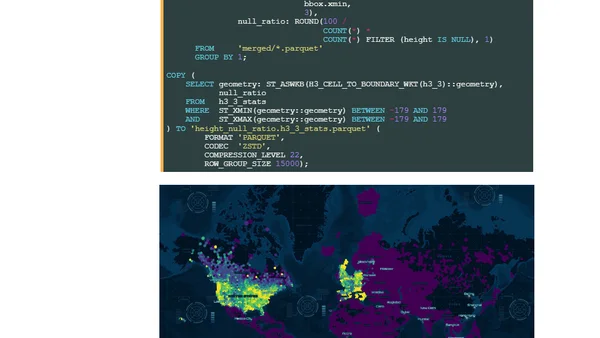
Microsoft's 2026 Global ML Building Footprints
Analysis of Microsoft's 2026 Global ML Building Footprints dataset, including technical setup and data exploration using DuckDB and QGIS.