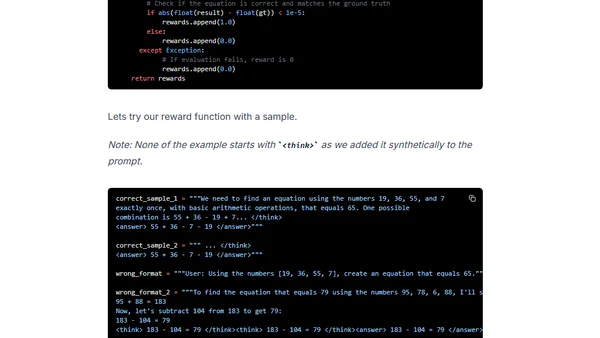
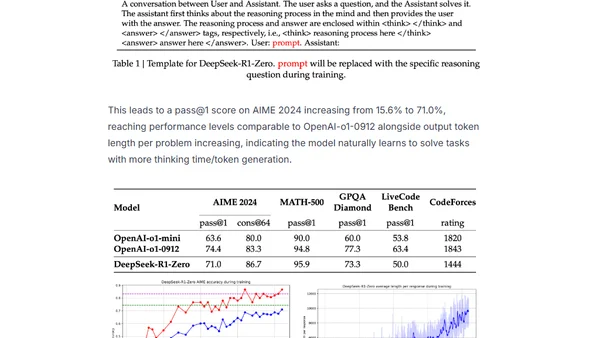
2/1/2025
•
EN
Finetune Granite3.1 for Reasoning
A technical guide on fine-tuning IBM's Granite3.1 AI model using Guided Reward Policy Optimization (GRPO) to enhance its reasoning capabilities.