Mini-R1: Reproduce Deepseek R1 „aha moment“ a RL tutorial
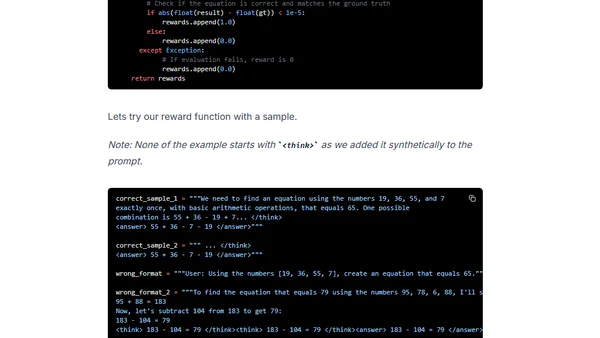
Read OriginalThis technical tutorial details how to replicate the reinforcement learning 'aha moment' from the DeepSeek R1 paper, where the model learned self-verification. It guides readers through using Group Relative Policy Optimization (GRPO) and Q-LoRA to train an open model on the Countdown numbers puzzle, covering setup, sample generation, and distributed training with Deepspeed and vLLM.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes