2/19/2026
•
EN
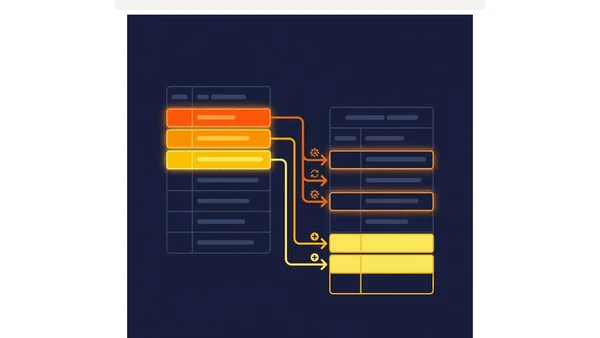
Data Quality Is a Pipeline Problem, Not a Dashboard Problem
Argues that data quality must be enforced at the pipeline's ingestion point, not patched in dashboards, to ensure consistent, reliable data.