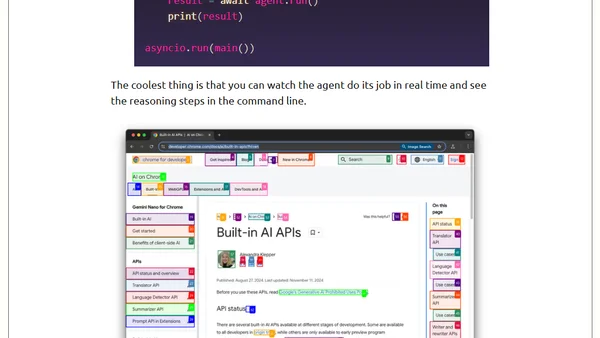
1/26/2026
•
EN
I'm swearing off APIs entirely
A developer explains why they are giving up on building apps that rely on external APIs due to access issues, ethical concerns, and platform risks.