Data Engineering in 2022: Exploring LakeFS with Jupyter and PySpark
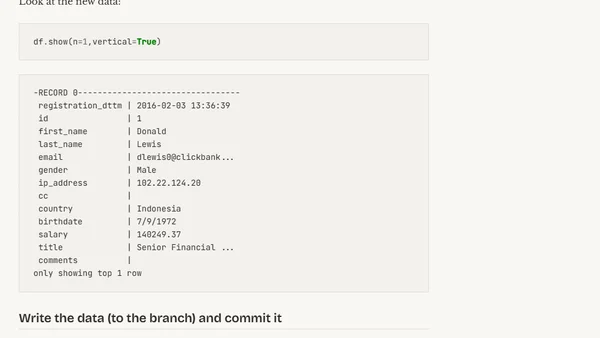
Read OriginalThis technical article details a practical experiment with LakeFS, a tool that brings Git-like version control to data lakes. The author uses PySpark and Jupyter notebooks to demonstrate branching, merging, and copy-on-write operations on Parquet data stored in S3-compatible storage (MinIO), highlighting its benefits for data engineering workflows.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes