Scale LLM Inference on Amazon SageMaker with Multi-Replica Endpoints
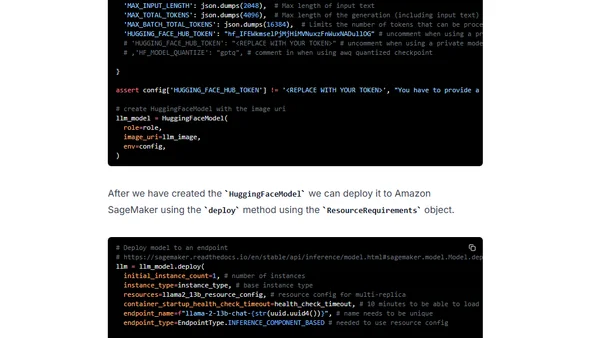
Read OriginalThis technical tutorial explains how to use Amazon SageMaker's new Hardware Requirements object to deploy multiple replicas of a Large Language Model (LLM), like Llama 13B, on a single instance (e.g., p4d.24xlarge). It covers setup with the SageMaker SDK, configuring the Hugging Face LLM DLC, and deploying models to optimize inference performance and cost.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes