Optimize and Deploy BERT on AWS inferentia2
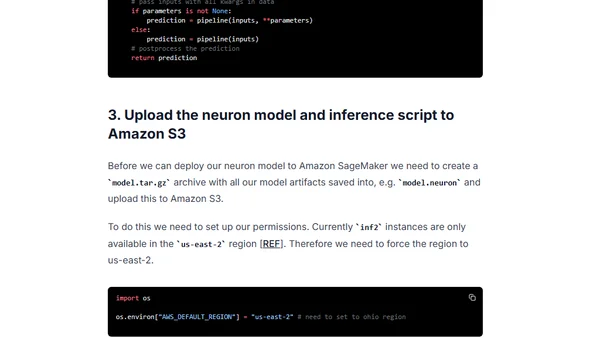
Read OriginalThis technical guide provides an end-to-end tutorial for optimizing a BERT model (specifically FinBERT) for deployment on AWS Inferentia2. It covers converting the model using Hugging Face's Optimum Neuron, creating a custom inference script, uploading to Amazon S3, deploying a real-time SageMaker endpoint, and achieving latency as low as 4ms for BERT-base.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes