Multimodal Function Calling with Gemini 3 and Interactions API
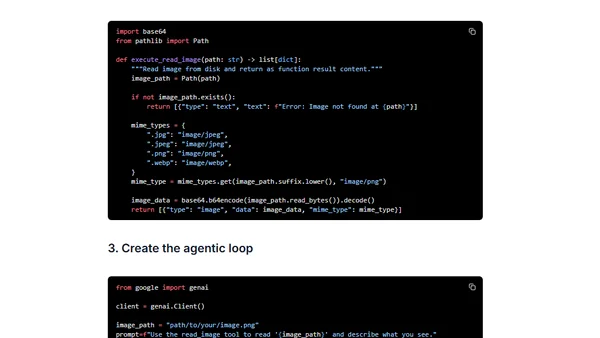
Read OriginalThis technical tutorial explains how to implement multimodal function calling using Google's Gemini 3 model and the Interactions API. It demonstrates how to build AI agents that can natively process images returned by tools, enabling use cases like coding agents reading UI screenshots or research agents analyzing charts. The article includes code examples for defining a tool, implementing image reading from disk, and creating an agentic loop.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes