Accelerate Mixtral 8x7B with Speculative Decoding and Quantization on Amazon SageMaker
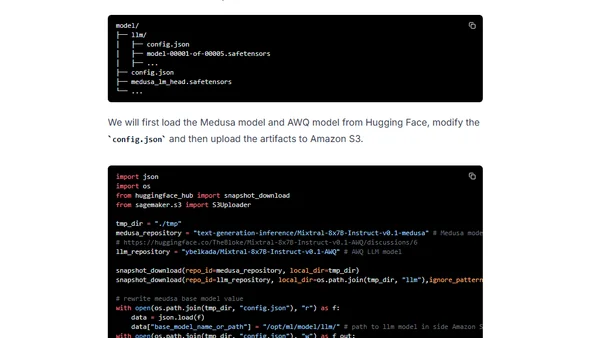
Read OriginalThis detailed tutorial explains how to deploy and accelerate the Mixtral-8x7B-Instruct-v0.1 model on Amazon SageMaker. It covers the use of speculative decoding via Medusa to predict multiple tokens and Activation-aware Weight Quantization (AWQ) to reduce memory footprint. The guide walks through setting up the environment, preparing artifacts with the Hugging Face LLM DLC, deploying to a g5.12xlarge instance, and achieving improved inference latency.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes