Serious Data From Testing LLMs
Read OriginalThe article presents a detailed experiment testing four Large Language Models (LLMs) on their ability to retrieve ingredients from a text containing multiple recipes. The author argues for evidence-based AI testing over blind faith, shares raw and analyzed data, and discusses the methodology as a model for responsible AI evaluation. It is a technical critique aimed at software testing and AI reliability.
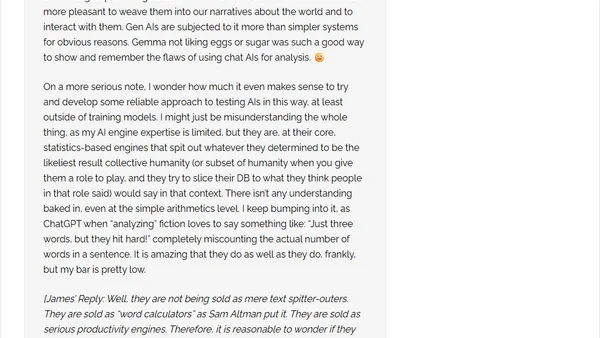
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
The Beautiful Web
Jens Oliver Meiert
•
2 votes
2
When your coding agent doesn’t understand your project, you’ll get junk
Benjamin Cane
•
1 votes
3
LLM Use in the Python Source Code
Miguel Grinberg
•
1 votes
4
Wagon’s algorithm in Python
John D. Cook
•
1 votes
5
An example conversation with Claude Code
Dumm Zeuch
•
1 votes